Oct
04
2019
Oct
04
2019
Three use cases for Artificial Intelligence and Machine Learning available today for the Legal Sector
By: Albert Jan Wonnink, Consulting Developer Epona Legal
For a while now, Artificial Intelligence (AI) and Machine Learning (ML) have been hyped as promising technologies that could revolutionize the Legal Sector. Promises of robot lawyers aside, we decided it was time for a more practical approach. As with every new technology we adopt at Epona Legal, we focus on how it will make life easier for lawyers, paralegals and supporting staff alike and help them take what we call “The Next Step”. Therefore, we developed new AI and ML based tools that I want to explain to you in this blog. In both tests and production we’ve already seen great results when comparing our own algorithm to those of the “big boys” in IT-Wonderland.
AI, faster and more consistent
Before we dive in to the tools, I want to address why we think Artificial Intelligence is the right technology for the described jobs. Artificial Intelligence is able to look at documents in a more consistent and faster way than humans. The bad examples of “computer bias” aside (Let’s not talk about the discriminating Amazon resumé selector), algorithms are able compare a new piece of content to a much larger volume of historical data at once than humans.
Where we humans can only judge based on what we remember, AI is able to judge based on everything that it has ever seen or has in its database. AI doesn’t forget, thus it will be more consistent in its outcome. However, we do still believe humans should have the final say in very relevant matters. AI is mostly faster, but that doesn’t mean it is always right. That’s why most of our AI based tools result in suggestions, instead of direct actions.
1. Speeding up and simplifying e-mail filing
We developed a new tool for DMSforLegal that works as a sidebar in Outlook, which analyses in- and outbound e-mails, and makes a suggestion as to which matter the e-mail should be filed in. This works based on a Machine Learning algorithm that basically analyses all available info in the e-mail (subject, content, sender, receiver(s) etcetera), changes it all in to number patterns, and compares it to the patterns of all other available e-mails already in your DMS. All data is stored and remains in your own Microsoft tenant. The entire analyses is executed by the algorithm within the confinements of the said tenant and never leaves your organization.
For example: You receive an e-mail from John Doe containing the subject: “Contract for Acme Corp” and an e-mail body text in the lines of “Hi Jim, please find attached the agreed upon and co-signed contract and NDA for Acme Corp project Omega.”. Every word in this sentence is converted into a number. So let’s say the algorithm identifies the words: Contract, Acme corp, Project Omega and NDA and attaches mathematically generated numbers. It does so for every word, but I picked out these because they are sort of unique to the sentence, unlike words like “please” or “the”. Now the algorithm will look in the DMS for matters concerning the number that’s associated with “Acme Corp”, and if then it also finds the number for “Project Omega”, the so called probability rate (the higher the number, the more certain the algorithm is that this matter is the right one) will become pretty high.
The Outlook sidebar will automatically show a list of clients or matters that the e-mail should be filed in, with the probability rating. Now the user can file the e-mail to the correct matter with only the click of a button. This saves the user loads of time because he doesn’t have to manually search the relevant matter. Also, this means that when each e-mail had to be matched manually, some users would choose not to file e-mails if they considered them to be less important to the matter. This meant that tiny bits of information that might have been relevant to other users could go lost due to another users, let’s call it, laziness. Now there is no more excuse to not file your e-mails.
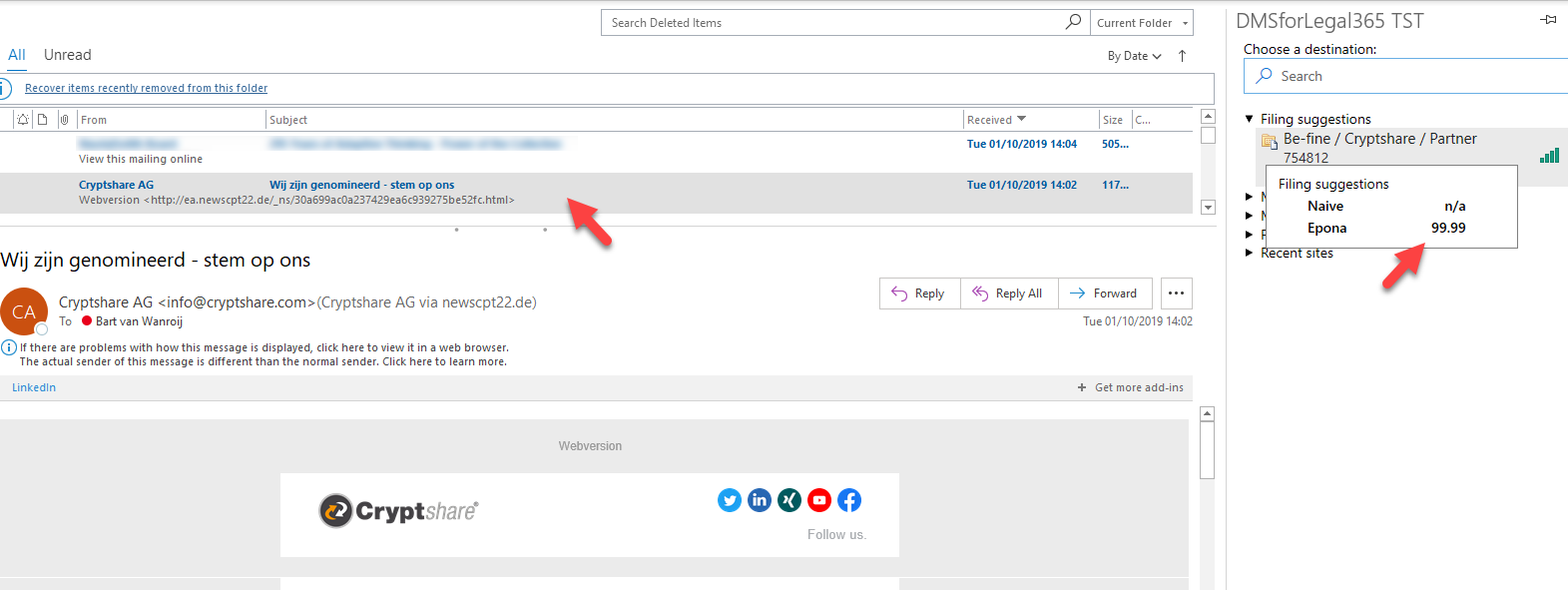
E-mail filing suggestions by AI
2. Improving findability of existing and new content
One of the best ways to improve the understanding of a piece of content for a computer is through metadata. In prespecified fields, users manually add relevant tags. Or at least, we hope they do. Because like with manually filing e-mails this isn’t one of your users most favorite jobs. What if the computer would be able to do this for them?
The process is very similar to the one I described with e-mail filing. An algorithm checks the content of a document or e-mail, turns the content into mathematically assigned numbers, compares it to patterns in existing documents of which it knows what it is, and then based on probability it automatically assigns metatags. And the good thing is, it doesn’t just do this for newly added content, but will also automatically classify existing content in your DMS.
The automatic tagging solves two problems at once:
One: users are relieved of very boring task.
Two: because documents are much more complete in metadata, users can use more refiners when searching for documents.
For instance, an NDA associated with a specific client can now be found by searching for the name of the client with a refiner for NDA’s. Instead of hoping the standard search algorithm figures out what you need instead of blurting out every file that has even a hint of your client’s name in it.
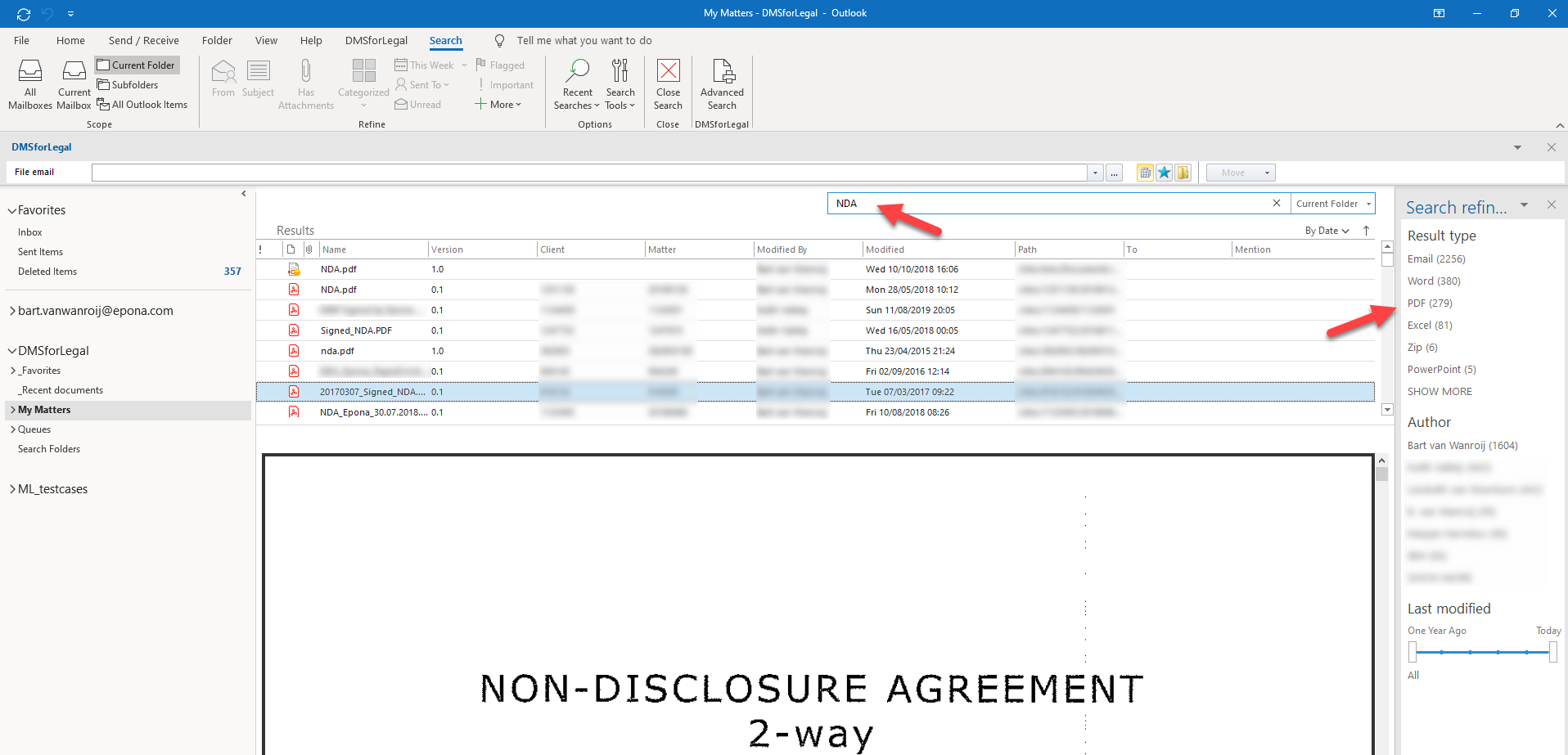
Search refiners created with AI
3. Whatever other e-mail or document management related task you need automated
Alright, the third one might be a bit of a tease, but the truth is that now that we’ve automated the afore mentioned tasks we’re hungry for more. We learned through the development of our algorithm and these two tools that almost every manual action regarding e-mail or content in your DMS can be automated through Artificial Intelligence and Machine Learning. So feel free to reach out to us and bring us your challenges. We can help make the daily life of your co-workers a lot easier because mundane and boring tasks get automated away and they can focus on what matters most in your line of business: the client (And billable hours, of course…)